C++에서의 몇 가지 의문 사항에 대한 정리
http://anyflow.net/category/프로그래밍%20노트/plfm.neutral
http://anyflow.net/category/프로그래밍%20노트/plfm.neutral
Q: 다음 프로그램에서 아레 TestFunc()와 TestFuncSecond()는 어느 class에 있는 함수가 불리겠는가?
class CBase {
public:
int m_base;
void TestFunc(void);
virtual void TestFuncSecond(void);
};class CDerived : public CBase {
public:
void TestFunc(void);
virtual void TestFuncSecond(void);
virtual void TestFuncThree(void) { };
};class COther : public CBase {
public:
int m_other;
void TestFunc(void);
virtual void TestFuncSecond(void);
};class CAnother : public COther {
public:
int m_another;
void TestFunc(void);
virtual void TestFuncSecond(void);
};//
void CBase::TestFunc() { m_base = 3; }
void CDerived::TestFunc() { m_base = 3; }
void COther::TestFunc() { m_base = 3; }
void CAnother::TestFunc() { m_base = 3; }void CBase::TestFuncSecond() { m_base = 3; }
void CDerived::TestFuncSecond() { m_base = 3; }
void COther::TestFuncSecond() { m_base = 3; }
void CAnother::TestFuncSecond() { m_base = 3; }int _tmain(int argc, _TCHAR* argv[])
{
CDerived *derived;
CAnother another;derived = (CDerived *)&another;
derived->TestFunc();
derived->TestFuncSecond();return 0;
}
#include <iostream>
#include <string>
#include <locale>
#include <cstdlib>
using namespace std;
int main(void)
{
wcin.imbue( locale( "korean" ) );
wcout.imbue( locale( "korean" ) );
const int bottom=0, top=100;
int source;
for( ;; ) // loop infinity
{
wcout << bottom << L"부터 " << top;
wcout << L"까지의 자연수를 입력해주세요." << endl;
wcin >> source;
if( source>=bottom && source<=top )
break;
else
wcout << L"입력형식이 잘못되었습니다. 다시 입력해주세요." << endl;
}
wstring unit( L"십백천만" );
wstring num( L"일이삼사오육칠팔구" );
wstring output;
for( int i=source,j=-1 ;; i/=10,++j ) // no condition.
{
if( j==-1 && ( i%10 != 0 ) )
output = num.substr( ( i%10 )-1, 1 );
else if( i%10 != 0 )
output = num.substr( ( i%10 )-1, 1 )+unit.substr( j, 1 )+output;
else if( source == 0)
output = L"영";
else
; // do nothing;
if( i < 10 )
break;
}
wcout << output << endl;
return EXIT_SUCCESS;
}
Static은 그 대상이 되는 해당 변수 내지는 멤버함수가 메모리상의 변하지 않는 정적 공간에 컴파일타임 혹은 링크타임에 '정적으로 바인딩 되어 고정된다'는 의미입니다.이를 제대로 이해하려면 컴퓨터의 데이터가 메모리 공간상에서 어떻게 구성되어 저장되는지를 알아야 합니다. 우리가 데이터를 저장하기 위해 사용할 수 있는 영역은 다음과 같습니다.
레지스터 영역, 코드영역, 데이터영역, 스택영역, 힙 영역
물론 이밖에도 시스템의 여러 데이터를 저장하기위한 공간이 따로 마련되어 있지만 여기서는 사용자가 접근 할 수 있는 부분에 대해서 다루므로 논외로 하겠습니다.
각각의 영역은 다음과 같은 역할을 합니다.레지스터 영역 : CPU내에 존재하는 영역으로 CPU의 연산 결과 값이나 중간값 등을 저장하는 공간으로 C언어에서는 자주 쓰이는 빠른 연산을 필요로 하는 데이터들을 넣는데 사용하고 있습니다. 레지스터는 용량이 제한되기 때문에 매우 한정된 데이터만을 저장할 수 있고 C언어에서는 사용가능한 레지스터 이외의 데이터들은 자동변수로 변환되어 메모리상에 기억됨니다.
코드영역 : 우리가 작성하는 코드 즉 오퍼레이션들이 저장되는 공간입니다.
데이터영역 : 이곳이 우리가 공부하고 있는 Static변수나 초기화된 변수 Global로 선언된 변수들이 저장되는 영역입니다.
스택영역 : 이곳에는 지역변수나 함수의 리턴 값등 잠시 사용되었다가 사라지는 데이터들을 저장하는 영역입니다. 씨언어에서는 기본적으로 이곳에 데이터는 저장하고 해제하게됩니다.
힙영역 : 흔히 동적데이터 영역이라고도 부르는 공간으로 메모리 주소값에 의해서만 참조되고 사용되는 영역입니다. 이곳에 데이터를 저장하기 위해 C언어에서는 malloc()이라는 함수를 지원하고 있습니다.
C언어에서는 기본적으로 AUTO로 스택 영역에 공간을 할당하고 데이터를 저장합니다. 사용된 데이터는 함수를 벗어나거나 블록을 벗어나면 사라져 버리게 됨니다. 하지만 우리가 프로그램을 작성하다보면 계속적으로 유지되어야 하는 변수가 존재하기 마련입니다. 이와같은 데이터들은 Global이나 Static으로 선언하여 주면 해당 변수는 데이터 영역에 공간이 할당 되고 값이 저장하게 됨니다.
그렇다면 Global변수와 Static은 같은 것이 아닐까 하는 의문을 제기할 수도 있을 것입니다.
Global의 경우는 전역변수라는 의미로 모든 블록문이나 함수에게 공개되어 있는 영역을 의미합니다. 이는 데이터 영역에 동적으로 할당되어 사용되고 , 프로그램이 끝나면 사라집니다.
Static은 말 그대로 정적인 데이터 영역으로 컴파일할때 혹은 링크시 데이터가 저장될 공간이 지정되게 됨니다. 또한 이렇게 선언된 데이터 영역은 유효성을 가지는데 어떠한 함수에서만 사용하게도 선언할 수 있습니다. 이렇게 선언된 데이터는 프로그램이 끝날때까지 유지되고 프로그램이 종료되면 사라집니다. 각 데이터 타입은 각 저장되는 공간과 선언되는 위치에 따라 여러 명칭으로 불리고 조합되어 사용될 수 있습니다. 그 조합 예는 다음과 같습니다.
1) local static 변수 : 일반적으로 로컬변수는 스택 영역에 생성되며, 해당 함수가 호출되는 시점에 따라 로컬 변수가 바인딩되는 주소가 달라지게 됩니다. 이는 static의 정의에 위배되는 일이죠. 따라서 로컬변수를 static으로 선언하면 컴파일 과정에서 전역 데이터 영역에 변수를 생성하고 그 위치에 변수의 주소를 바인딩합니다. 전역데이터영역은 프로그램 수행동안 침범되지 않는 영역이므로 안전하게 정적으로 바인딩된 주소를 유지할 수 있습니다.
2) global static 변수 : local변수는 static으로 선언될 때 전역 데이터 영역에 생성된다고 했습니다. 전역 데이터 영역은 다른 곳이 아니라, 바로 전역변수가 자리잡는 영역이죠. 그런데 전역변수를 static으로 선언했을경우, 전역변수는 이미 전역 데이터 영역에 자리잡는 변수이므로 위치는 그전과 같습니다. 하지만 전역static변수가 그냥 전역 변수와 다른 점은 반드시 '컴파일타임'에 바인딩될 수 있어야 한다는 것입니다.
전역변수의 경우, extern키워드로 다른 모듈의 전역변수를 링크해서 사용할 수 있습니다. 여기서 중요한 것은 extern키워드로 선언한 전역변수는 링크 타임에 메모리의 위치가 바인딩되어 결정된다는 것이지요. static 개체는 위에서 말했듯이, '컴파일타임'에 메모리 바인딩이 결정되어야 합니다.
따라서 static으로 선언한 전역변수는 다른 모듈에서 extern으로 링크해서 사용할 수 없습니다.
3) static member 변수 : 클래스의 일반적인 멤버변수는 this포인터를 기반으로 오프셋이 얼마.. 라는 식으로 멤버변수의 주소를 계산하게 됩니다. 즉, 이 말은 어떤 변수를 참조할때, 메모리상의 어떤 주소에서 값을 가져와야 하는지는 실제 객체가 생성된 후인 런타임에서야 알 수 있다는 것이죠. 따라서 클래스의 멤버로 선언된 스태틱 변수는 컴파일타임에 로컬 스태틱 변수와 마찬가지로 전역 데이터 영역에 바인딩되어 사용됩니다. 그 결과로 해당 클래스의 모든 객체에서 동일한 변수를 사용하게 되는 것이지요.
사실, 스태틱 멤버 변수의 메모리 바인딩은 정확히는 링크 타임에 결정됩니다만.. 클래스 멤버의 경우에는 this를 기반으로 한 메모리 위치의 계산이 이루어지지 않는 다는 것에 초점이 맞춰진 언어설계라고 하겠습니다.
4) static member 함수 : 이 역시 멤버변수의 논의와 동일합니다. static 멤버함수는 그 함수 내에서 직접 참조하는 요소가 컴파일타임에 결정될 수 있을 것을 요구합니다. 즉, this포인터에 의해 위치가 변하는 멤버변수의 참조가 금지됩니다. 따라서 스태틱 멤버함수에서는 this포인터의 사용이 금지되지요. 그렇게 함으로써 static멤버만 접근할 수 있는 것이죠. 일반 멤버는 객체가 생성된 후인 런타임에만 그 위치를 결정할 수 있기 때문에 접근을 제한하도록 하는 메커니즘입니다.
또한, virtual 멤버함수는 어떤 함수가 실행될지는 런타임에 동적으로 바인딩된다는 것을 알려주는 키워드입니다. 따라서 당연히 정의로부터 static과 정면으로 대치되는 개념이지요. 결과적으로 한 멤버함수가 static이면서 동시에 virtual일수는 없습니다.
그리고 함수 뒤쪽에 static을 붙이는 선언 구문은 없습니다. 아마도 const지정자를 함수 뒤쪽에 붙이는 것에서 오해를 하신듯 한데, const지정자를 함수 앞에 붙일 경우 리턴 타입이 const인 것을 지정하는 구문과 구분할 수 없게 되므로 궁여지책으로 const지정자는 함수이름 뒤쪽으로 가게 된 것이죠.
하지만 static지정자는 함수 앞에 붙어도 다른 것과 혼동될 여지가 없으므로 앞에 붙게 되는 것입니다.
32비트 머신에서 4바이트의 리틀엔디언 메모리 읽는 법.
01 00 10 00
-> 0x00100010
07 53 00 00
-> 0x00005307
VC에서 문서개요에 대한 기능 설명을 찾기위해
구글에서 "VC" +"문서개요" 로 검색을 했다가
Out of The Ocean 이란 이름의 블로그를 발견했다.
재미있는 내용이 많다.
여기서 한 가지 요즘 공감하는 글을 발견했다.
회사에 대한 고민은 회사 사람에게 이야기 하지 말라.
그 배신감... 다시금 살아난다.
자주 놀러 가야지..
Out of The Ocean
malloc을 통해서 동적 메모리 할당을 할때,
char *a = (char*)malloc(17);
a를 위와 같이 17만큼만 할당 후,
fread(a, 1, 20, fp); 와 같이 할당 받은 사이즈 보다 많은 값을 읽고난 후
char *b = (char*)malloc(17); 했을때 예외가 발생함...
따라서 동적 메모리 할당시 사용하는 메모리를 잘 계산해서 사용할 것.
문제 발생 소스는 너무 커서 생략.
#include "stdafx.h"
using namespace std;
int _tmain(int argc, TCHAR* argv[], TCHAR* envp[])
{
int a[5] = {1, 2, 3, 4, 5};
int* pb = &a[3];
cout << (-2)[pb] << endl;
return 0;
}
이 코드의 결과는?
#include <iostream>
using namespace std;
class Base{
int a;
public:
virtual void func1(){
cout << "func1" << endl;
}
virtual void func2(){
cout << "func2" << endl;
}
};
class Derived : public Base{
int b;
public:
virtual void func1(){
cout << "D::func1" << endl;
}
virtual void func3(){
cout << "func3" << endl;
}
};
class Derived2 : public Derived{
int c;
public:
virtual void func1(){
cout << "D2::func1" << endl;
}
virtual void func3(){
cout << "D2::func3" << endl;
}
virtual void func4(){
cout << "func4" << endl;
}
};
int main()
{
Base a;
a.func1();
Derived b;
b.func3();
Derived2 c;
c.func3();
return 0;
}
가상함수 테이블 샘플
Base 클래스의 가상함수 테이블만 보인다.
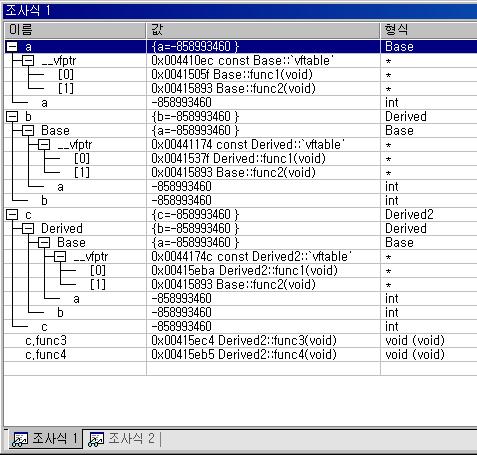
원문: http://blog.naver.com/baboneo/80007502224
union을 사용하면 공간 절약, 큰 놈 쪼개기 등의 장점외에도...
**
union SVertexf
{
struct
{
float x, y, z;
};
float v[3];
};
...
SVertexf v;
// 인간적인-_- 구조체 멤버에 접근해서 직관적으로 값을 대입하기도 하고
v.x = 3.0;
v.y = 2.0;
v.z = 5.0;
...
// 요런게 편할 때는 또 요렇게 하기도 하고
glVertex3f(v.v[0], v.v[1], v.v[2]);
glVertex3fv(v.v);
**
행렬도 비슷하게 처리하면 직관성과 for나 while 등 Loop의 장점도 살릴 수 있어 좋다.
이때 한 가지 주의할 점은...
공용체 내 서로 다른 구조체에서 변수 이름 충돌 시 먼저 정의된 변수가 우선한다는 거다.
에러 안남! -_-
따라서 같은 크기의 구조체에서 대응되는 위치에 동일한 이름이 사용될 경우
아무런 오류없이 돌아간다. 하지만 다른 이름 짓기를 권장함!
char** pArrStr = new char*[10];
for (int i = 0; i < 10; i++) {
pArrStr[i] = new char[20];
sprintf(pArrStr[i], "Hello World - %d", (i + 1));
}
for (int j = 0; j < 10; j++) {
cout << pArrStr[j] << endl;
delete [] pArrStr[j];
}
delete [] pArrStr;
// [] 하지 않았을때 소멸자가 한번만 실행됨.
// 원시타입일 경우 차이 없음.
malloc 도 위와 같음.
추가.
동적할당 메모리 누수 체크
stdafx.h 파일과 같이 모든 소스에서 include 하는 파일에 추가.
#define _CRTDBG_MAP_ALLOC
#include <stdlib.h>
#include <crtdbg.h>
#define new new(_NORMAL_BLOCK, __FILE__, __LINE__)
main() 에 추가.
_CrtSetDbgFlag ( _CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF );
C++에서 double형을 int형으로 casting해서 사용할 때 소숫점이 절산된다
#include
#include
using namespace std;
int main(void) {
double dt = 15.25-14.74;
cout << floor(dt * 100.0) << endl;
cout << (int)(dt * 100.0) << endl;
cout << floor(dt * 100.0+0.5) << endl;
cout << (int)(dt * 100.0+0.5) << endl;
return 0;
}
실행결과
50
50
51
51
문제는 위의 2개의 결과인데, dt값이 0.51이기 때문에 *100하면 51이되어서 51이 출력될 줄 알았는데 50이 출력된다. int casting을 하지 않으면 51이 나온다.
모든수가 그런것은 아니고 몇몇수가 그렇다.
A)dt 값이 0.51이 아닌 0.509xx 등등이 될 수 있다.
부동소수점 표현법은 근사치로만 사용할 수 있기 때문. dt 값을 %f 로 출력해보면 0.50999999999999979 이 나온다.
1.virtual 로 선언을 하면 가상 함수로 설정이 된다.
2.가상함수로 설정이 되면 함수의 실행 모듈을 코딩하지 않아도 가
능하다.
3.가상함수로 설정할때 장점은 상위 클래스에는 필요가 없으나 하
위클래스에서 필요할경우 상위에 virtual로 선언하고 상위 클래스
로 모든 프로그램을 구동시킬때 사용한다.
4.객체를 후에 업그레이드 할경우 virtual 로 선언한후에 차후에
해당 프로그램의 기능을 넣는 방식에 해당한다.
5.객체 지향방식의 프로그래밍에서 발전 부분및 통합 연동의 대표
적인 기능
-sample-
#include <iostream.h>
#include <string.h>
class CGbtObject
{
protected:
int style;
int x1;
int y1;
public:
virtual void print();
void setdata(int s,int x,int y);
};
void CGbtObject::print()
{
cout << style << ",";
cout << x1 << ",";
cout << y1 << "\n";
}
void CGbtObject::setdata(int s,int x,int y)
{
style=s;
x1=x;
y1=y;
}
class CStrObject:public CGbtObject
{
public:
char str[20];
virtual void print();
};
void CStrObject::print()
{
cout << style << ",";
cout << x1 << ",";
cout << y1 << ",";
cout << str << "\n";
}
void main()
{
CStrObject a;
a.setdata(1,2,3);
strcpy(a.str,"test");
a.print();
}
1.클래스에서 내부에 있는 특정 맴버 함수만 외부에서 사용하고자
할때 static 로 선언한다.
2.static 로 선언되면 해당 함수는 내부 클래스의 맴버 함수들을
접근 할수 없는 독립 호출 함수가 된다.
3.사용불가 예
class CTest{
protected:
int data;
public:
static int getdata(int d)
{
d+data //사용 불가
};
};
-sample-
#include <iostream.h>
#include <string.h>
#include <stdio.h>
class CStr
{
public:
char string[80];
static char* Strcpy(char *d,char *s);
char *Strcpy(char *s);
};
char* CStr::Strcpy(char *d,char *s)
{
strcpy(d,s);
return d;
}
char* CStr::Strcpy(char *s)
{
strcpy(string,s);
return string;
}
void main()
{
CStr str;
char data[80],data2[80];
cin >> data;
CStr::Strcpy(data2,data);
cout << data2;
cin >> data2;
str.Strcpy(data2);
cout << str.string;
}
1. malloc
- malloc함수의 리턴값은 요구한 메모리를 얻으면 메모리의 시작주소를 리턴해주고 얻지 못하는 경우에는 NULL을 리턴해 준다. NULL은 주소값이 없다는 것을 뜻한다.
2. malloc과 calloc의 차이
- malloc함수는 요구한 메모리를 초기화 하지 않는 반면에 calloc함수는 요구한 메모리의 값을 0으로 초기화 해준다
3. realloc함수는 할당 받은 메모리의 크기를 변경하기 위한 함수이다. 재할당 받는 함수이다. 메모리의 크기를 크게하던 작게하던 상관은 없다. 다만 재 할당을 받아도 그전에 저장했던 내용은 저장이 된다.
4. 동적메모리를 왜 사용하는가???
- 메모리에 누수가 생기면 시스템에 커다란 해를 끼칠 수 있다면 동적 메모리를 사용하지 않는 것이 좋다.
원문 : http://joinc.co.kr/modules.php?name=News&file=article&sid=105&mode=nested
이 문서는 C에 익숙하지만 C++ 에는 아직 익숙치 않은 프로그래를 위한 문서이다. 비록 이제 막 C++ 로 입문하고자 하는 C 언어 사용자의 "팁"수준의 지침서 정도가 되겠지만, C++을 꽤 사용했던 프로그래머에게도 몇가지 도움이 될만한 힌트가 있을것이다.
차례
1절. C프로그래머를 위한 C++
1.1절. 새로운 include 방법
1.2절. 라인단위 주석사용
1.3절. 간단하게 사용할수 있는 입출력 스트림
1.4절. 변수선언 위치제한
1.5절. 전역변수와 지역변수의 동일이름 사용
1.6절. 변수의 상호참조가능
1.7절. namespace 의 선언
1.8절. inline 함수의 사용
1.9절. 예외처리
1.10절. default 인자사용 가능
1.11절. Parameters Overload
1.12절. Operator overload
1.13절. template
1.14절. 메모리 할당/해제
1.15절. Class
1.16절. 생성자 / 소멸자
1.17절. 클래스 메서드의 선언과 정의 분리
1.18절. 객체의 배열
1.19절. 클래스 멤버변수의 static 선언
1.20절. 클래스 멤버변수의 상수선언
1.21절. this 포인터
1.22절. 상속
1.23절. 다중상속
1.24절. 캡슐화(은닉)
1.25절. 가상함수
1.26절. 파일스트림 처리
1.27절. 정형화된 출력
1.28절. 문자배열을 file 처럼이용하기
--------------------------------------------------------------------------------
1절. C프로그래머를 위한 C++
1.1절. 새로운 include 방법
C++ 에서는 헤더파일을 인클루드 시키기 위해서 새로운 방법을 사용한다. C++ 에서는 C의 표준 헤더파일을 인클루드 시키기 위해서 ".h" 확장자를 사용하는 대신에 ".h"를 생략하고 헤더파일의 가장앞에 "c" 를 붙여서 인클루드 시킨다. 제대로된 인클루드를 위해서 "using namespace std;" 를 포함시키도록 한다. 표준 C++ 헤더는 확장자를 생략하면 된다 - 생략하지 않아도 문제는 없지만 -.
물론 기존의 C 스타일대로 헤더파일을 인클루드 시켜도 문제는 없다. 그러나 어떤 컴파일러의 경우(gcc 3.x 와 같은) 디버깅 옵션을 켜놓은 상태에서 컴파일할경우 warning 메시지를 출력하기도 한다. // stdlib.h -> cstdlib
#include <cstdlib>
#include <iostream>
using namespace std;
int main()
{
char *age = "25";
cout << atoi(age) << endl;
}
--------------------------------------------------------------------------------
1.2절. 라인단위 주석사용
C 에서와 마찬가지로 // 를 이용한 라인단위 주석의 사용이 가능하다. #include <cstdlib>
#include <iostream> // iostream 라이브러리 사용
using namespace std; // 표준 라이브러리 namespace 지정
int main()
{
char *age = "25";
cout << atoi(age) >> endl; // 출력
return 1; // 종료
}
--------------------------------------------------------------------------------
1.3절. 간단하게 사용할수 있는 입출력 스트림
C 에서는 간단한 화면/키보드 입출력이라도 꽤 번거로운 과정을 거쳐야 하지만, C++ 에서는 cout <<, cin >> 을 이용해서 간단한 입출력을 쉽게 처리할수 있다. #include <iostream>
using namespace std;
int main()
{
int age;
char name[32];
cout << "hello world " << endl;
cout << "your age : ";
cin >> age;
cout << "your name : ";
cin >> name;
cout << "Your input is " << name << ":" << age << endl;
}
--------------------------------------------------------------------------------
1.4절. 변수선언 위치제한
C 의 경우 변수 선언은 함수의 가장첫부분에서 이루어져야 한다. 만약 중간에 선언이 이루어진다면, 컴파일시 에러를 발생하게 된다.
C++ 은 어느 위치에서라도 선언해서 사용할수 있다. 이러한 점이 때로는 코드를 난잡하게 만들기도 하지만, 오히려 코드를 보기쉽게 만들어줄때도 있다. #include <iostream>
using namespace std;
int main()
{
int a, b;
cout << "A : " ;
cin >> a ;
cout << "B : " ;
cin >> b ;
int sum;
sum = a + b;
cout << a << "+" << b << "=" << sum << endl;
}
--------------------------------------------------------------------------------
1.5절. 전역변수와 지역변수의 동일이름 사용
C 에서는 전역변수와 지역변수가 이름이 같을경우 무조건 지역변수의 값만을 사용할수 있었으나(전역변수 값은 사용 할수가 없다), C++ 에서는 각각 구분해서 사용가능하다. #include <iostream>
using namespace std;
int my_age = 28;
int main()
{
int my_age = 35;
cout << "Local my_age " << my_age << endl;
cout << "global my_age " << ::my_age << endl;
return 0;
}
--------------------------------------------------------------------------------
1.6절. 변수의 상호참조가능
다음과 같은 방법으로 하나의 변수를 다른변수에서 참조하여 사용하는게 가능하다. #include <iostream>
using namespace std;
int main()
{
int a = 200;
int &b = a;
b = 100;
cout << "a is " << a << endl;
return 0;
}
위의 코드를 실행시키면 100 이 출력된다.
--------------------------------------------------------------------------------
1.7절. namespace 의 선언
namespace 를 이용해서 변수의 선언이 가능하며 :: 연산자를 통해서 선언 없이 곧바로 변수의 이용이 가능하다. #include <iostream>
using namespace std;
namespace first
{
int a;
int b;
}
namespace second
{
int a;
int b;
}
int main()
{
first::a = 100;
first::b = 200;
second::a = 400;
second::b = 800;
cout << first::a + second::a << endl;
cout << first::b + second::b << endl;
}
--------------------------------------------------------------------------------
1.8절. inline 함수의 사용
간단한 함수들은 inline 으로 선언해서 사용함으로써 몇가지 잇점을 얻을수 있다. inline 으로 선언된 함수는 일종의 macro 와 같이 작동을 하게 된다. 즉 필요할때 불러오는 방식이 아니라, 코드에 바로 insert 된 효과를 준다. 이것이 주는 잇점은 코드가 약간 커지긴 하겠지만, 빠른 실행 속도를 보장해 준다는 점이다. #include <iostream>
#include <cmath>
using namespace std;
inline double mysqrt(double a, double b)
{
return sqrt (a * a + b * b);
}
int main()
{
double k = 6, m = 9;
// 밑의 2개의 라인은 실행시에 완전히
// 동일하게 작동한다.
cout << mysqrt(k, m) << endl;
cout << sqrt(k*k + m*m) << endl;
return 0;
}
inline 인것과 아닌것의 차이를 비교해보고 싶다면, g++ -S 를 이용해서 어셈코드를 얻은다음에 직접 비교 해보기 바란다.
--------------------------------------------------------------------------------
1.9절. 예외처리
당신이 C에서 사용하고 있다면, for, if, do, while, switch 와 같은 키워드들를 알고 있을것이다. C++ 에서는 예외처리(EXECPTION)와 관련된 또다른 키워드들을 제공한다. 선택문 혹은 예외처리를 위한 좀더 직관적이고 손쉬운 프로그래밍 작업을 가능하도록 도와준다. #include <iostream>
#include <cmath>
using namespace std;
int main()
{
int age;
char *no_vote[] = {"없습니다", "있습니다."};
cout << "당신의 나이는 ? ";
cin >> age;
try
{
if (age > 18) throw 1;
else throw 0;
}
catch(int result)
{
cout << "당신은 투표권이 " << no_vote[result] << endl;
}
return 0;
}
--------------------------------------------------------------------------------
1.10절. default 인자사용 가능
함수의 인자를 사용할때 기본 인자를 설정할수 있다.
#include <iostream>
using namespace std;
int mysqrt(int a, int b = 2)
{
int c = 1;
for (int i =0; i < b; i++)
{
c *= a;
}
return c;
}
int main()
{
cout << mysqrt(5) << endl;
cout << mysqrt(5, 5) << endl;
}
--------------------------------------------------------------------------------
1.11절. Parameters Overload
C++ 의 중요한 잇점중에 하나가 인자를 통한 함수 오버로드가 가능하다는 점이다. 오버로드 기능을 이용함으로써, 서로 다른 연산을 수행하는 함수를 하나의 이름으로 관리 가능 하도록 도와주며, 이는 코드의 유지/보수/가독성을 높여준다. #include <iostream>
using namespace std;
double add (double a, double b)
{
return a+b;
}
int add (int a, int b)
{
return a+b;
}
int main()
{
cout << add(1, 2) << endl;
cout << add(1.2, 2.4) << endl;
}
--------------------------------------------------------------------------------
1.12절. Operator overload
함수인자를 통한 오버로드 뿐만 아니라, 기본적인 연산자들의 오버로드역시 가능하다. 다시 말해서 연산자의 정의를 다시 내릴수 있도록 한다. #include <iostream>
using namespace std;
struct vector
{
double x;
double y;
};
vector operator * (double a, vector b)
{
vector r;
r.x = a * b.x;
r.y = a * b.y;
return r;
};
int main()
{
vector k, m;
k.x = 2;
k.y = 4;
m = 3.141927 * k;
cout << "(" << m.x << "," << m.y << ")" << endl;
return 0;
}
연산자 오버로는 사칙연산자 외에도 +=, ++, [], (), << 등을 포함한 약 40개 이상의 연산자에 대해서도 가능하다. #include <iostream>
using namespace std;
struct vector
{
double x;
double y;
};
ostream& operator << (ostream & o, vector a)
{
o << "(" << a.x << "," << a.y << ")" ;
return o;
}
int main()
{
vector k;
k.x = 2;
k.y = 4;
cout << k << endl;
cout << "hello "<< endl;
return 0;
}
--------------------------------------------------------------------------------
1.13절. template
함수 오버로딩이 꽤 편하긴 하지만, 몇가지 불편함이 있다. 즉 인자의 갯수만큼의 함수를 만들어줘야 한다. 만약 int, float, double 연산을 위한 오버로드된 함수를 만들고자 한다면, 거의 똑같은 3개의 함수를 정의해야만 한다. template 를 사용하면 인자의 자료형에 관계없이 사용가능한 (범용한) 함수의 제작이 가능하다. #include <iostream>
using namespace std;
template <class T>
T mymin (T a, T b)
{
T r;
r = a;
if (b < a) r = b;
return r;
}
int main()
{
cout << "Litle is : " << mymin(2, 100) << endl;
cout << "Litle is : " << mymin(2.6, 2.4) << endl;
}
위의 템플릿을 이용한 코드는 꽤 괜찮게 작동하긴 하지만, 한가지 문제가 있다. 위의 코드는 인자의 타입이 동일해야 한다. 만약 인자가 각각 int, double 타입을 가진다면, 컴파일시 에러를 발생시킬것이다. 이문제는 템플릿을 선언할때 서로 다른 인자를 받아들일수 있도록 선언하면 된다. #include <iostream>
using namespace std;
template <class T1, class T2>
T1 mymin (T1 a, T2 b)
{
T1 r, converted;
r = a;
converted = (T1) b;
if (converted < a) r = converted;
return r;
}
int main()
{
cout << "Litle is : " << mymin(2, 100) << endl;
cout << "Litle is : " << mymin(2.6, 2.4) << endl;
cout << "Litle is : " << mymin(3.4, 3) << endl;
}
그외에도 비교연산을 제대로 수행하기 위한 형변환이 필요할 것이다.
--------------------------------------------------------------------------------
1.14절. 메모리 할당/해제
메모리 할당과 해제를 위해서 new 와 delete 키워드를 사용할수 있다. 이들은 C 에서 사용하는 malloc, free 대신 사용할수 있다. 만약 배열의 할당을 원한다면 new[] delete[] 를 사용하면 된다. #include <iostream>
#include <cstring>
using namespace std;
int main()
{
int *d;
// int 형을 포함할수 있는 새로운 메모리 공간확보하고
// 주소를 되돌려준다.
d = new int;
*d = 21;
cout << "Type a number : ";
cin >> *d;
cout << *d + 5 << endl;
// 할당받은 메모리 영역을 해제한다.
delete d;
// 15개의 int 형자료를 저장할수 있는 새로운 메모리
// 공간을 확보하고, 주소를 되돌려준다.
d = new int[15];
d[0] = 1234;
d[1] = d[0] + 1234;
cout << d[0] << ":"<< d[1] << ":" << d[2] << endl;
delete []d;
return 0;
}
--------------------------------------------------------------------------------
1.15절. Class
간단히 생각해서 Class 란 발전된 형태의 struct 이다. 데이타와 함께, 데이타를 가공할 METHODS 가 선언될수 있다. 다음은 Class 설명을 위한 간단한 예제이다. #include <iostream>
#include <cstring>
using namespace std;
class vector
{
public:
double x;
double y;
inline double surface()
{
double s;
s = x*y;
if (s < 0)
s = -s;
return s;
}
};
int main()
{
vector a;
a.x = 3;
a.y = 4;
cout << a.surface() << endl;
return 0;
}
위의 예제코드에서 a를 클래스 vector 의 인스턴스(INSTANCE)라고 한다.
--------------------------------------------------------------------------------
1.16절. 생성자 / 소멸자
만들수 있는 메서드 중에는 생성자(Constructor)와 소멸자 (Destructor), 이것들은 인스턴스가 생성되고 소멸될때 자동적으로 호출되는 메서드이다.
생성자는 인스터스의 여러가지 변수를 초기화하거나, 메모리 할당등의 작업을 위해서 쓰인다. 다음은 오버로드된 2개의 생성자를 이용한 셈플코드이다. #include <iostream>
using namespace std;
class vector
{
public:
double x;
double y;
vector()
{
x = 0;
y = 0;
}
vector(double a, double b)
{
x = a;
y = b;
}
};
int main()
{
vector k;
cout << "vector k: " << k.x << "," << k.y << endl;
vector m(45, 5);
cout << "vector m: " << m.x << "," << m.y << endl;
k = vector (22, 13);
cout << "vector k: " << k.x << "," << k.y << endl;
}
하지만 이미 앞에서 배운 default parameter 을 사용하면, 번거롭게 overload 하지 않고 코드를 단순화 시킬수 있다. #include <iostream>
using namespace std;
class vector
{
public:
double x;
double y;
vector(double a = 0, double b = 0)
{
x = a;
y = b;
}
};
int main()
{
vector k;
cout << "vector k: " << k.x << "," << k.y << endl;
vector m(45, 5);
cout << "vector m: " << m.x << "," << m.y << endl;
vector p(5);
cout << "vector p: " << p.x << "," << p.y << endl;
}
소멸자는 그리 필요하지 않는경우가 많다. 보통은 인스턴스가 제대로 종료되었는지 확인하고, 종료될때 어떤 값을 가지고 종료되는지 알고자하는 목적(DEBUG) 으로 많이 사용된다. 그러나 만약 인스턴스에서 메모리 할당을 했다면 (new 나 malloc 로) 인스턴스를 종료시키기 전에 반드시 메모리를 해제(free) 시켜줘야 한다. 이럴경우 소멸자는 매우 유용하게 사용된다. #include <iostream>
using namespace std;
class person
{
public:
char *name;
int age;
person(char *n ="no name", int a = 0)
{
name = new char[40];
strncpy(name, n, 40);
age = a;
}
~person()
{
cout << name << " : 40 byte is free : Instance going to be deleted" << e
ndl;
delete []name;
}
};
int main()
{
person me("yundream", 25);
cout << "name is " << me.name << endl;
cout << "age is " << me.age << endl;
person *my;
my = new person("hello");
cout << "name is " << my->name << endl;
cout << "age is " << my->age << endl;
delete my;
return 0;
}
(할당된 메모리는 free 를 하거나 프로세스가 종료되지 않는한은 커널에 되돌려지지 않는다.)
--------------------------------------------------------------------------------
1.17절. 클래스 메서드의 선언과 정의 분리
만약 메서드를 inline 으로 작성하고 싶지 않다면, 클래스에는 단지 선언만을 포함하게 유지하고, 메서드의 원형을 별도로 관리하도록 할수 있다. #include <iostream>
using namespace std;
class vector
{
public:
double x;
double y;
double surface();
};
double vector::surface()
{
double s= 0;
for (double i = 0; i < x; i++)
{
s = s + y;
}
return s;
}
int main()
{
vector k;
k.x = 5;
k.y = 6;
cout << k.surface() << endl;
return 0;
}
이렇게 분리할경우 inline 에 비해서 약간의 속도저하가 있을수 있겠지만, 유지/보수가 수월해질것이다.
--------------------------------------------------------------------------------
1.18절. 객체의 배열
당연히 객체를 배열로 선언하는 것도 가능하다. #include <iostream>
#include <cmath>
using namespace std;
class vector
{
public:
double x;
double y;
vector (double a=0, double b=0)
{
x = a;
y = b;
}
double module()
{
return sqrt (x*x + y*y);
}
};
int main()
{
vector t[3] = {vector(4,5), vector(5,5), vector(2,5)};
cout << t[0].module() << endl;
cout << t[1].module() << endl;
cout << t[2].module() << endl;
return 0;
}
--------------------------------------------------------------------------------
1.19절. 클래스 멤버변수의 static 선언
클래스 맴버변수는 static 로 선언될수 있으며, static 로 선언되었을경우 모든 인스턴스에서 공유해서 사용할수 있다. 단. static 으로 선언된 변수의 초기화는 클래스의 밖에서만 가능하다. #include <iostream>
#include <cmath>
using namespace std;
class vector
{
public:
double x;
double y;
static int count;
vector (double a=0, double b=0)
{
x = a;
y = b;
count ++;
}
~vector()
{
count --;
}
};
int vector::count = 0;
int main()
{
cout << "Number of vector : " << endl;
vector a;
cout << vector::count << endl;
vector b;
cout << vector::count << endl;
vector *r, *u;
r = new vector;
cout << vector::count << endl;
u = new vector;
cout << vector::count << endl;
delete r;
cout << vector::count << endl;
delete u;
cout << vector::count << endl;
return 0;
}
위의 vector 클래스는 count 라는 static 변수를 가지고 있다. 이 변수는 현재 vector 클래스의 인스턴스의 갯수를 계수하기 위한 용도로 사용된다. vector 클래스의 새로운 인스턴스가 만들어지면 count 를 증가하고 인스턴스가 소멸되면 count 를 감소시킴으로써 인스턴스의 갯수를 유지한다.
--------------------------------------------------------------------------------
1.20절. 클래스 멤버변수의 상수선언
클래스 멤버변수가 static 로 선언되는것과 마찬가지로 상수 (constant)로 선언될수도 있다. 이 변수는 클래스안에서 값이 할당되며, 인스턴스에서 변경될수 없다. 그러나 단지 const 로만 선언했을경우 컴파일러에 따라서 컴파일이 안될수도 있다. 예를들어 gnu 컴파일러의 경우 const static 로 선언해야 될경우가 있다. #include <iostream>
#include <cmath>
using namespace std;
class vector
{
public:
double x;
double y;
const static double pi = 3.1415927;
vector (double a=0, double b=0)
{
x = a;
y = b;
}
double cilinder_volume()
{
return x*x/4*pi*y;
}
};
int main()
{
cout << "pi is: " << vector::pi << endl;
vector k (3,4);
cout << "Result: " << k.cilinder_volume() << endl;
return 0;
}
--------------------------------------------------------------------------------
1.21절. this 포인터
클래스에서 각 메서드는 주소에 의한 방식으로 함수를 호출한다. 이렇게 할수 있는 이유는 this 라는 가상의 포인터 때문이다. 클래스에 선언된 모든 메서드는 this 를 명시하지 않더라도 this 가 있는것으로 간주되고 주소에 의해서 함수가 호출된다. 이렇게 하는 이유는 클래스내의 멤버함수를 객체에 의해서 소유하도록 하기 위함이 목적이다. 즉 this 는 보이지 않는 포인터로 객체와 멤버함수를 내부적으로 연결하는 일을 한다. #include <iostream>
#include <cmath>
using namespace std;
class vector
{
protected:
double k;
public :
double x;
double y;
vector(double a= 0, double b= 0)
{
x = a;
y = b;
}
double module()
{
cout << "module " << x << " : " << y<< endl;
return sqrt(x*x + y*y);
}
void set_length(double a = 1)
{
double length;
length = this->module();
x = x/length *a;
y = y/length *a;
}
};
int main()
{
vector a(3,5);
cout << "--> " << a.module() << endl;
a.set_length(2);
cout << "--> " << a.module() << endl;
a.set_length();
cout << "--> " << a.module() << endl;
}
--------------------------------------------------------------------------------
1.22절. 상속
클래스는 다른 클래스로 부터 파생(Derived)될수 있다. 이 새로운 클래스는 원본클래스의 메서드와 변수를 상속 (Inherits) 받게 된다. 이렇게 해서 파생된 클래스는 새로운 메서드와 변수들을 추가함으로써 확장시켜 나갈수 있게 된다.
#include <iostream>
#include <cmath>
using namespace std;
// 원본 클래스
class vector
{
public:
double x;
double y;
const static double pi = 3.1415927;
vector (double a=0, double b=0)
{
x = a;
y = b;
}
double surface()
{
return x * y;
}
};
// vector 로부터 파생된 새로운 클래스
// 원본 vector 클래스의 표면적을 구하는 작업외에
// 체적을 구하는 작업을 할수있도록 확장되었다.
class trivector: public vector
{
public :
double z;
// trivector 생성자가 호출되기 전에
// vector 생성자가 호출되어서 m, n 인자를
// 초기화 한후, 거기에 3차원 지원을 위해서 p 가
// 초기화 된다.
trivector(double m =0, double n =0, double p=0): vector(m,n)
{
z = p;
}
// 또다른 생성자로 만약에 2차원 정보가
// 들어왔을경우 3차원으로 변경한다.
trivector(vector a, double p = 0)
{
x = a.x;
y = a.y;
z = p;
}
// 3차원 데이타를 이용해서 체적을 구한다.
// surface()메서드를 호출해서 표면적을 구하고
// 거기에 높이인 z 를 곱해주면 된다.
double volume()
{
return this->surface() * z;
}
};
int main()
{
vector a(4, 5);
trivector b(1, 2, 3);
trivector c(a);
cout << "surface a: " << a.surface() << endl;
cout << "volume b: " << b.volume() << endl;
cout << "surface b: " << b.surface() << endl;
cout << "volume c: " << c.volume() << endl;
trivector d(a,5.8);
cout << "volume d: " << d.volume() << endl;
}
--------------------------------------------------------------------------------
1.23절. 다중상속
바로 위에서 상속에 대해서 알아봤는데, C++ 은 1개 이상의 클래스로 부터 상속받는 것도 가능하다. 그러나 다중상속을 이용해서 클래스를 만들경우 나중에 유지/보수가 곤란해지는 문제가 생길수 있음으로, 대체적으로 다중상속은 지양하는 추세이다. #include <iostream>
#include <cmath>
using namespace std;
// 원본 클래스
class vector
{
public:
double x;
double y;
const static double pi = 3.1415927;
vector (double a=0, double b=0)
{
x = a;
y = b;
}
double surface()
{
return x * y;
}
};
class height
{
public :
double z;
height (double a)
{
z = a;
}
int is_negative()
{
if (z < 0) return 1;
else return 0;
}
};
class trivector: public vector, public height
{
public :
trivector(double a= 0, double b=0, double c=0): vector(a,b), height(c)
{
}
double volume()
{
return fabs(x* y* z);
}
};
int main()
{
trivector a(2, 3, -5);
cout << a.volume() << endl;
cout << a.surface() << endl;
cout << a.is_negative() << endl;
}
--------------------------------------------------------------------------------
1.24절. 캡슐화(은닉)
아마 당신이 C++ 을 처음접해 보았다면, 위의 코드에서 public: 라고 하는 생소한 키워드를 보았을것이다. 이것은 C++ 에서 새로추가된 키워드로 메서드나 멤버변수에 엑세스레벨을 부여하게 된다.
public: 는 프로그램어디에서든지 엑세스 할수 있음을 나타낸다. 이것은 원본클래스와 파생클래스에게 모두 동일하게 적용된다.
private: 는 단지 원본 클래스의 메서드를 통해서만 접근이 가능하다.
protected: private 와 비슷하게 클래스 메서드를 통해서만 접근이 가능하지만, private 와는 달리 원본뿐 아니라 파생된 클레스에서의 접근도 가능하다.
#include <iostream>
#include <cmath>
using namespace std;
class vector
{
private:
double x;
double y;
public :
double surface()
{
return x * y;
}
};
int main()
{
vector b;
b.x = 2; // 컴파일 에러발생
b.y = 3; // 컴파일 에러발생
}
위의 경우 c++ 컴파일러로 컴파일할경우 `double vector::x' is private 와 같은 에러메시지를 출력하고 컴파일 중지된다. vector 클래스의 멤버변수 x, y 는 private 로 선언되어 있음으로 단지 현재 클래스의 메서드를 통해서만 접근가능하기 때문이다. 이럴경우 x, y 입력을 위한 전용 메서드를 하나 만들어야 할것이다. #include <iostream>
#include <cmath>
using namespace std;
class vector
{
private:
double x;
double y;
public :
double surface()
{
return x * y;
}
void input(double a, double b)
{
x = a;
y = b;
}
};
int main()
{
vector b;
b.input(11, 40.5);
cout << b.surface() << endl;
}
--------------------------------------------------------------------------------
1.25절. 가상함수
원본클래스에서 파생된 새로운 클래스는 원본 클래스의 메서드와 멤버변수를 상속받는다는 것을 배워서 알고 있다. 그런데 이런경우를 생각할수 있을것이다. vector 에 module 란 메서드가 있는데, 이 메서드는 다음과 같다. double module()
{
return sqrt(x*x + y*y);
}
만약 vector 에서 파생된 trivector 이란 클래스를 선언했다면, trivector 클래스는 vector->module() 를 상속받게 될것이다. 그러나 trivector 의 경우 sqrt 연산을 할때 3차원 데이타를 가지고 연산을 해야 할것이다. double module()
{
return sqrt(x*x + y*y + z*z);
}
이처럼 메서드를 상속받았을때, 상속받은 메서드의 연산방식이 변경될경우 virtual 로 선언하면 된다. #include <iostream>
#include <cmath>
using namespace std;
class vector
{
public :
double x;
double y;
virtual double module()
{
return sqrt(x*x + y*y);
}
};
class trivector: public vector
{
public :
double z;
trivector(double m=0, double n=0, double p=0)
{
x = m;
y = n;
z = p;
}
double module()
{
return sqrt(x*x + y*y + z*z);
}
};
int main()
{
trivector b(2,3,4);
cout << b.module() << endl;
}
--------------------------------------------------------------------------------
1.26절. 파일스트림 처리
C++ 은 파일처리를 위한 매우 간단한 방법을 제공한다. 다음은 파일을 읽기 위한 코드이다. #include <iostream>
#include <fstream>
using namespace std;
int main()
{
fstream f;
char c;
f.open("seek3.c", ios::in);
while (! f.eof())
{
f.get(c);
cout << c;
}
f.close();
return 0;
}
다음은 파일에 쓰기 위한 코드이다. #include <iostream>
#include <fstream>
#include <cstdio>
using namespace std;
int main()
{
fstream f;
f.open("text.txt", ios::out);
f << "Hello world " << endl;
f.close();
return 0;
}
--------------------------------------------------------------------------------
1.27절. 정형화된 출력
보통 표준 C 언어에서는 printf 를 이용해서 정형화된 출력을 수행한다. C++ 에서는 width() 와 setw()를 이용해서 정형화된 출력을 한다. 이것들은 단지 가장최근의 출력에만 영향을 미친다. #include <iostream>
#include <iomanip>
using namespace std;
int main()
{
for (int i = 1; i <= 1000; i *=2)
{
cout.width(7);
cout << i << endl;
}
for (int i = 0; i <=10 ;i ++)
{
cout << setw(3) << i << setw(5) << i * i * i << endl;
}
return 0;
}
--------------------------------------------------------------------------------
1.28절. 문자배열을 file 처럼이용하기
좀 이상하게(혹은 쓸모없는 것처럼) 들릴수 있겠지만, 문자배열을 파일처럼 연산하는게 가능하다. 이것은 파일 스트림과 메모리를 연결해서 사용하는 프로그래밍 기법을 가능하도록 해준다. #include <iostream>
#include <cmath>
#include <cstring>
#include <strstream>
using namespace std;
int main()
{
char a[1024];
ostrstream b(a, 1024);
b.seekp(0); // 스트림의 첫번째로 이동
b << "2+2 = " << 2+2 << ends; // ends 임에 주의
cout << a << endl;
double v = 49;
strcpy(a, "A sinus: ");
b.seekp(strlen(a));
b << "sin (" << v << ") = " << sin(v) << ends;
cout << a << endl;
}
#include <iostream>
#include <cmath>
#include <cstring>
#include <strstream>
using namespace std;
int main()
{
char a[1024];
istrstream b(a, 1024);
strcpy(a, "45.656");
double k, p;
b.seekg(0);
b >> k;
k = k+1;
cout << k << endl;
strcpy(a, "444.23 56.89");
b.seekg(0);
b >> k >> p;
cout << k << ", " << p + 1 << endl;
return 0;
}
1. 클래스 생성자의 멤버 초기화는 멤버리스트를 통해서 하는 것이 안전하며 그 순서를 지켜야 한다.
2. 클래스 소멸자는 되도록 virtual로 선언한다. 이 클래스를 상속한 클래스가 있을 경우 virtual이 아닌 소멸자는 호출되지 않기 때문에 메모리 leak이 생긴다.
3. 클래스 생성자 함수에서 자식 클래스가 만드는 pure virtual function을 부르는 일이 없도록 한다. 치명적 오류의 원인.
자세한 것은 http://sparcs.kaist.ac.kr/~ari/each/article.each.605.html 에서 순서대로 '다음글' 링크를 따라 보면 된다.
원래 따라갔던 링크는 http://codian.net/blog/archive/0408211736330952_M_2005_02.html#050211110151TKJG 이다.
원문: http://blog.naver.com/woorara7/20017399440
/////////////////////////////////////////////////////////////////////
// char -> wchar
wchar_t* CharToWChar(const char* pstrSrc)
{
ASSERT(pstrSrc);
int nLen = strlen(pstrSrc)+1;
wchar_t* pwstr = (LPWSTR) malloc ( sizeof( wchar_t )* nLen);
mbstowcs(pwstr, pstrSrc, nLen);
return pwstr;
}
/////////////////////////////////////////////////////////////////////
// wchar -> char
char* WCharToChar(const wchar_t* pwstrSrc)
{
ASSERT(pwstrSrc);
#if !defined _DEBUG
int len = 0;
len = (wcslen(pwstrSrc) + 1)*2;
char* pstr = (char*) malloc ( sizeof( char) * len);
WideCharToMultiByte( 949, 0, pwstrSrc, -1, pstr, len, NULL, NULL);
#else
int nLen = wcslen(pwstrSrc);
char* pstr = (char*) malloc ( sizeof( char) * nLen + 1);
wcstombs(pstr, pwstrSrc, nLen+1);
#endif
return pstr;
}
//current - 리스트를 처음부터 끝까지 차례대로 검색할때 현재 위치.
//previous - 바로 전 위치.
//Next - 다음 위치.
#include < stdio.h >
#include < stdlib.h >
typedef struct _NODE{
char ch;
struct _NODE *next;
}NODE;
NODE *head;
void init(void);
void build(void);
void print(void);
void reverse(void);
int main(void){
init();
build();
print();
reverse();
print();
return 0;
}
void init(void){
head = (NODE*)malloc(sizeof(NODE));
head->next = NULL;
}
void build(void){
NODE *tmp1, *tmp2, *tmp3, *tmp4;
tmp1 = (NODE*)malloc(sizeof(NODE));
tmp2 = (NODE*)malloc(sizeof(NODE));
tmp3 = (NODE*)malloc(sizeof(NODE));
tmp4 = (NODE*)malloc(sizeof(NODE));
head->next = tmp1;
tmp1->next = tmp2;
tmp2->next = tmp3;
tmp3->next = tmp4;
tmp4->next = NULL;
tmp1->ch = 'A';
tmp2->ch = 'B';
tmp3->ch = 'C';
tmp4->ch = 'D';
}
void print(void){
NODE *index;
index = head->next;
while(index !=NULL){
printf("%c ", index->ch);
index = index ->next;
}
printf("\n");
}
void reverse(void){
NODE *index, *tmp, *tmp2;
index = head->next->next;
tmp = head->next;
tmp2 = head;
while(index->next != NULL){ //리버스 작업
tmp->next = tmp2;
tmp2 = tmp;
tmp = index;
index = index->next;
}
//마지막 작업
tmp->next = tmp2;
index->next = tmp;
head->next->next = NULL;
head->next = index;
}
//No.1
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct _QPACKET {
int nSize;
char data[0]; //<--- 이 부분 data가 길어지더라도 시작 번지를 갖고 있는다
} QPACKET;
void aaa(int nSize, char *data)
{
QPACKET *test;
int a = 0;
a = sizeof(int);
test = (QPACKET*) malloc(sizeof(int) + strlen(data) + 1); //<--- 데이터의 길이 만큼 동적 메모리 할당
test->nSize = nSize;
strcpy(test->data, data);
printf("R: %s\n", test->data);
free(test);
}
void main(){
char data[12];
strcpy(data, "abcde");
aaa(strlen(data), data);
}
//No.2
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
typedef struct _QPACKET {
int nSize;
char *data; <--- 이 부분
} QPACKET;
void aaa(int nSize, char *data)
{
QPACKET *test;
int a = 0;
a = sizeof(int);
test = (QPACKET*) malloc(sizeof(QPACKET));
test->data = (char *) malloc(strlen(data)+1); <--- malloc 한 번더
if(test->data==NULL){
printf("메모리 할당 실패\n");
}
test->nSize = nSize;
strcpy(test->data, data);
printf("R: %s\n", test->data);
free(test->data);
free(test);
}
void main(){
char data[12];
strcpy(data, "abcde");
aaa(strlen(data), data);
}
변수를 선언하면 메모리에 공간이 확보된다.
값을 변수에저장하면 변수에 데이타가 쓰여진다. 하지만 메모리에 읽고쓰는건 느리다. 그에비해 CPU의 속도는 빠르다. 메모리와 CPU의 속도차이로 CPU의 성능을 제대로 활용하지 못한다. 그런데 CPU내부에 메모리처럼 사용할수 있는 공간이 약간존재하는 이 곳을 register라고 한다. 많이 사용되는 변수를 이곳에 저장하면 속도가 빠르다.
컴파일러가 컴파일을 할때 자동으로 최적화시켜주는데 그중하나가 자동으로 register에 등록하는것입니다. 수동으로 레지스터에 등록할려면
ex) int x; ===> register int x; 로해주지만 보통 2개정도로 적은수만 가능합니다.
volatile은 이와반대로 저런 최적화를 방지하기 위한 키워드 입니다.
즉 자동 최적화를 하지말라는것을 컴파일러에 알려주는겁니다.
왜냐면 저런 자동최적화가 문제를 발생시키는경우가 있기때문입니다. 그렇다고 최적화를 막으면 프로그램수행속도가 떨어집니다. 따라서 프로그래머가 원하는것만 최적화시키지 말것을 명령하는 것이 volatile 입니다.
예제) 사용법은 일반적인 변수타입선언과 같습니다.
volatile int x; 혹은 int volatile x 같은 의미입니다.
필요한경우는 memory-mapped I/O 혹은 스레드 같은 곳에서 사용됩니다.

|

